融合多层语言知识的统计机器翻译
Statistical machine translation based on multi-level linguistic knowledge
自然语言处理
Natural Language Processing
实验室关于自然语言处理的研究有基础研究和应用开发两个方面。 前者涉及到词法、句法、语义分析,包括汉语分词、词性标注、注音、命名实体识别、新词发现、句法分析、词义消歧等。在此基础上,开发了文本分类、 旅游资源对话查询 、科技文献检索、机器翻译等应用系统。本研究得到了国家高技术研究发展计划(“863”计划)项目《智能中文搜索引擎技术研究及平台构建 》的支持。
There are two directions, i.e. basic oriented and application oriented. The former includes Chinese word segmentation, part-of-speech tagging, pinyin tagging, named entity recognition, new word detection, syntactic parsing, word sense disambiguation, etc . Based on these, a series of application systems are developed, including the text categorization system, the dialogue based travel information query system, the scientific literature retrieval system, and the machine translation system. The research is supported by the National High Technology Research and Development Program (863 Program).

自然语言处理框架
该项目多次参加国际和国内学术评测,并取得了很好的成绩,如:在2004年“863”计划中文信息处理与智能人机接口技术评测中取得了“中文命名体识别”任务的第一名;在2005年美国国家技术标准局举办的“自动内容抽取(ACE)”国际评测中取得了单项第一名;在2006年SIGHAN组织的中文分词国际评测中,取得单项第一名。
In participating domestic and international evaluations excellent achievements have been awarded:The 1st place in the named entity recognition task, “ 863” evaluations on Chinese
information processing and intelligent human-machine interface, 2004;
The 1st place in one task, NIST 2005 Automatic Context Extract (ACE) Evaluations;
The 1st place in one task, SIGHAN 2006 Chinese Word Segmentation Evaluations.
中文词法分析
Chinese Lexical Analysis
实验室基于统计机器学习理论和方法,结合汉语词法特点,在中文词法分析方面开展了深入研究,并开发了实用的高性能中文词法分析系统 。
Based on statistical machine learning theories and the morphological characteristics of Chinese language, a Chinese lexical analysis system was developed which demonstrated high performance.
词法分析的目的是找出句子中的各个词,进而给这些词添加上句法范畴标记乃至语义范畴标记。
The purpose of lexical analysis is to identify the words in the sentence and mark them with the syntactic tagging such as part of speech, and semantic tagging.
自动分词是中文词法分析的关键一步,与西方语言不同,中文的词和词之间没有显性的分隔 标记 。自动切分过程中会出现许多歧义,例如下图中只有红色标记的切分结果是正确的。
Automatic segmentation is a key step in the Chinese lexical analysis, because Chinese sentences are composed with the string of characters without spaces to mark word boundaries. When segmenting automatically , there may exist disambiguation. For instance, in the following figure, only the segmentation marked with the red color is correct.

自动分词
Automatic segmentaion
词性标注是根据词义及其上下文信息,标注出其在句中所属词类的过程,属于句法范畴的标注。
Part of speech tagging, as part of syntactic tagging, is to mark each word's part of speech in
a sentence, according to its definition and context.

词性标注
POS tagging
中文新词自动检测
Chinese New Word Detection
社会发展导致新词语不断涌现。从自然语言中自动发现新词——新词自动检测,已成为自然语言处理的热点之一。有效的新词自动检测对于提高分词、命名体识别、自动问答、机器翻译的性能具有重要作用。
With the rapid progress of the society, new words come out continuously. New Word Detection is one of the most critical issues in Chinese word segmentation, a fundamental research topic in Chinese natural language processing.
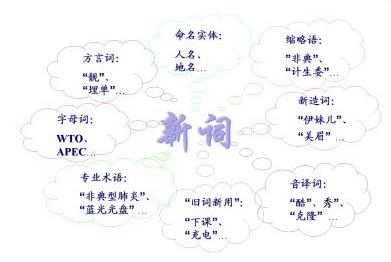
新词大多是领域相关的术语,并且具有时间敏感性。从语言学角度来讲,汉语中的新词语按照来源大体可以分为几类,如右图所示。
These new words are mostly domain specific terms and time sensitive terms. From the linguistics point of view, Chinese new words can be categorized as shown in the right diagram according to their derivations.
| 
|

中文新词自动检测流程图
Flow Chart of Chinese New Word Detection
本研究基于统计的方法,采用PAT数组这种目前比较流行的全文检索索引技术,对语料库进行全文索引,得到语料库中各种字频、词频、最长重复字符串等信息。利用这些频率信息计算词语SCPCD连接测度提取新词。
With statistical approaches, the popular technology of document search index — PAT Array is used to find the frequency information of characters, words, and longest repeated character strings, and extract the new words according to the SCPCD (Symmetric Conditional Probability and Context Dependency) association measurement.
实体检测与跟踪
Entity Detection and Tracking
实体检测与跟踪是自然语言处理的关键技术,也是信息抽取、自动问答、机器翻译等技术的重要基础。
As a kind of critical technology in natural language processing, entity detection and tracking are also important in the field of information extraction, automatic question answering and machine translation.
实体检测是指在数据文件或数据库中识别出特定类别的命名性实体、一般名词性实体或代词性实体等,如:人物、地点、组织机构名称等。它是一个类别标记的分类问题,通过训练分类器识别出实体的边界及类别。
Entity detection is to identify the named, nominal and pronominal entities from the text, such asperson,location,organization, etc. This task is usually formulated as a classification problem, through training proper classifiers to mark each entity's border and type 。
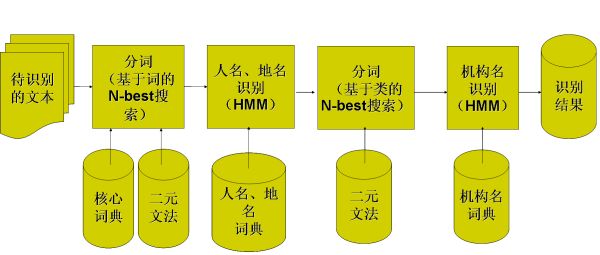
实体检测流程图
Flowchart of Entity Detection
实体跟踪是指解决同一个实体不同表达之间的互指关系,即指代消解。指代消解过程通常被分为两个阶段:训练分类器判定指代概率;根据指代概率对实体表达进行聚类。
Entity tracking, also named coreference resolution, is to identify the same object from different mentions. Usually it consists of two steps: First, obtaining the reference probability from trained classifiers; second, clustering all mentions that refer to the same entity according to the reference probability.

实体检测与跟踪示意图
Diagram of Entity Detection and Tracking
自动文本分类
Automatic Text Categorization
自动文本分类是对大量的自然语言文本按照一定的主题自动分类。它是自然语言处理的一个重要分支,主要应用于信息检索、机器翻译、自动文摘、信息过滤、邮件分类等领域。
Text categorization, the task of automatically assigning one or more categories to free text documents according to their contents, is an important component in many information management missions, and is widely applied in information retrieval, machine translation, automatic text summarization, information filtering and mail classification, etc.
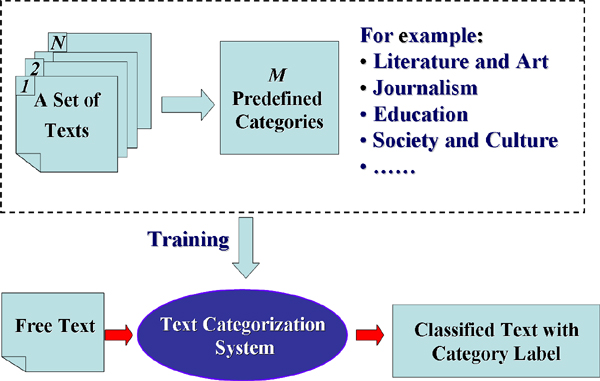
文本分类系统框架
The system framework of text categorization
基于野点学习的文本分类算法研究
Outliers Learning Based Text Categorization
样本野点定义为无意义网页、错误标记的网页、位于多类类别边界上的网页、类别属性超出预先定义 类别标记集的网页等。本研究采用基于系综学习的野点学习方法剔除网页中的噪声样本,有效地提高了文 本分类的性能。
The main kinds of outliers include: the samples mislabeled or lying on the borders between different categories; the samples that are out of the defined categories and the garbage samples. Based on the ensemble learning method, the outliers are learned and deleted from the training corpus.
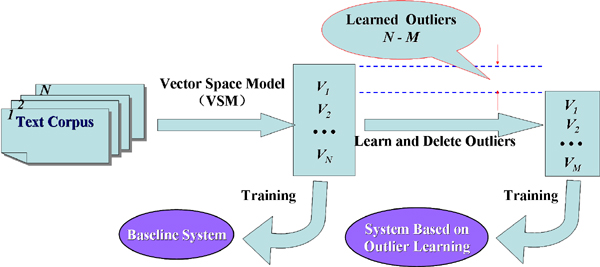
系统构建流程
The diagram of system construction
统计机器翻译
Statistical Machine Translation
统计机器翻译是利用基于语料库训练得到的统计参数模型,将源语言的文本翻译成目标语言,它是机器翻译的主流方向。
Statistical Machine Translation (SMT) is the text translation by the statistical parameter models obtained from the training corpus, which has become the mainstream of machine translation research.
统计机器翻译原理
Principle of the SMT
给定源语言句子,系统在所有候选目标语言句子中,基于统计模型选择概率最大的句子作为翻译结果。
Given a source sentence , and based on the statistical model ,the system selects the string with the highest probability by statistical model from all possible target sentences .
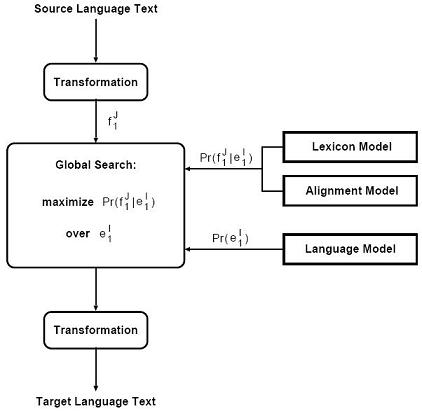
统计机器翻译原理图
Principle of the SMT
|
|
并行化模型训练系统
Parallel Training System —PGIZA
统计机器翻译模型的训练需要处理大量训练语料,这通常需要大型服务器才能实现。 本研究基于分布式计算,在集群机上实现了并行化模型训练系统-PGIZA,从而极大地提高了工作效率,降低了对计算设备的要 求。
The training module of SMT involves a large amount of corpus which was usually implemented in mainframe servers. A new parallel training system PGIZA was designed and implemented in a computer cluster, which demonstrated the high feasibility.

并行化模型训练系统
Parallel Training System
| 

