音视频信息的抽取、融合、挖掘和检索
Information extraction, fusion, mining and retrieval from audio and video
实验室的研究主要包含音视频信息的抽取、融合、挖掘和检索.基于音视频的抽取和检索目的在于从日益增多的语音数据中有效地检索文档,扩展获取信息的手段。
The research of the laboratory mainly includes information extraction, fusion, mining and retrieval from audio and video. The aim of this research is to improve document retrieval and expand means of extracting information from the growing voice data.
| 大词汇量连续语音识别 (Large vocabulary continuous speech recognition)
言语是人们交流信息的最自然和最方便的一种手段,也是人机交互的重要媒界之一。本课题旨在研究和开发一个具有自然交谈风格的大词汇量连续语音识别系统。本研究得到了国家自然科学基金重点项目《基于感知学习和语言认知的智能计算模型》,以及青年基金项目《多层语言知识建模及其语音识别全局解码算法研究》的支持。
Speech is the most natural and convenient way for human communication, and one of the most important media for human-machine interaction. The research will lead to a new recognition system for the spontaneous and conversational speech. This research has been supported by the Key Project and Young Scientist Project of Natural Science Foundation of China (NSFC).
PULSAR系统
本研究实现的系统PULSAR包括:基于听感知机理的抗噪声特征提取,针对汉语发音特点的声学建模,基于加权有限状态自动机(WFST)的搜索空间,融合声学模型和语言模型的高效全局解码。 2003年以来多次参加国家“863”组织的学术评测,并取得了较好成绩。
| 
The PULSAR system is developed with the following parts: the robust feature extraction based on auditory mechanisms, acoustic modeling with mandarin pronunciation characteristics, search space building based on WFST, and efficient global decoding scheme. The PULSAR has participated the academic evaluations organized by national “863” (National High Technology Research and Development Program ) since 2003, and got good grades.
|
| 音频识别系统及检索技术(Audio recognition and retrieval technology)
利用自主开发的PULSAR语音识别系统及信息检索技术,设计实现了一套高效的语音检索系统。该系统包括语音识别、语音文档索引及检索回放三个模块,能够对海量的语音数据进行快速、准确的识别,并建立相对精确的索引。
By taking advantage of the information retrieval technologies and the PULSAR, a high performance speech document retrieval system was developed, its three major modules are speech recognition, document indexing and playback. The system recognizes mass speech data fast and accurately, and builds indexes precisely.
高性能声音分类技术自动定位分割节目中的语音段及音乐、噪音段;自动判断语音的录音环境及说话人属性;并调用相应的声学模型进行识别。该技术为准确的语音识别奠定了基础。
Sound Classification TechnologyHigh performance sound classification technology is the cornerstone of speech recognition, which can automatically segment the speech, music and noise, mark the recording environment, distinguish different speakers, and apply corresponding acoustic models.
快速语音识别引擎采用高效的语音识别解码器,构建快速语音识别引擎,识别速度达到1.1倍实时。
Recognition EngineThe high speed speech recognition engine can reach the speed of 1.1x real time, thanks to the high performance speech recognition decoders.
| 
系统框架(System Architecture)
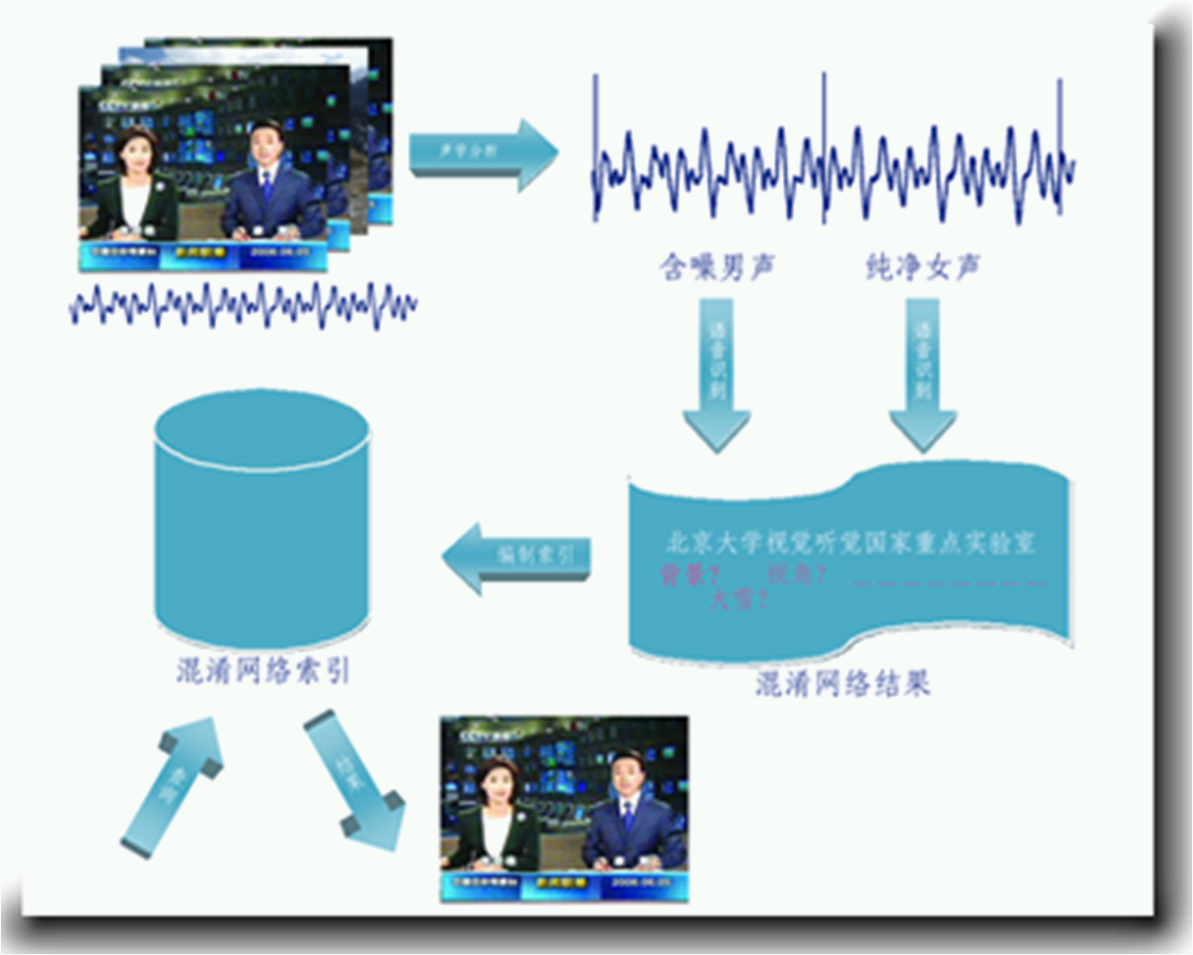
基于混淆网络构造语音文档索引目前的语音识别技术并不能保证100%的正确率,通过混淆网络技术,保留若干易混淆候选结果,使未能正确识别的段落得到正确索引,可有效地保证查全率。
Confusion NetworkUsing indexing technology based on confusion network, the recall rate can be preserved even though the recognition rate is not perfect.
|
说话人识别 (Speaker Recognition)
说话人识别是一项重要的生物特征识别技术,具有自然、方便等特点。它分为说话人辨识和说话人确认,在智能人机界面、司法鉴定以及场景监控等方面具有广阔的应用前景。本研究在国家自然科学基金重大项目、重点项目、“973”计划、“863”计划等多年支持下,取得了一系列成果。
Speaker Recognition is a natural and convenient biometric technology that can be applied in intelligent user interface, forensics and surveillance. It is usually divided into two categories, i.e. speaker identification and speaker verification. This research is supported by a series of national key projects and has made good progress.
实验室提出了基于听觉计算模型、模块化神经网络、高斯混合模型、隐马尔科夫模型等说话人识别方法,以及结合语义和声纹信息的说话人识别框架。
The laboratory has proposed several speaker recognition methods involving computational auditory models, modular neural networks, Gaussian mixed models, hidden Markov models, and implemented a recognition framework combining semantic and voiceprint information.
| 
自2004年起多次参加美国国家技术标准局举办的说话人识别国际评测,并在2004年电话交谈语音的说话人识别评测中取得了第一名的成绩。
The group has regularly participated in the Speaker Recognition Evaluation held by the USA National Institute of Standard and Technology (NIST) since 2004, and won the top 1 inthe speaker recognition task for telephone conversation speech in 2004.
|
语种识别 (Language Recognition)
多语言智能人机交互技术是语音识别领域中的研究热点。语种识别是多语言人机接口的重要组成部分,主要用于系统前端。
Multilingual intelligent human-machine interaction is a hot spot in the field of speech recognition. Language recognition is a significant component of multilingual human-machine interface, as the front end of a speech recognition system.
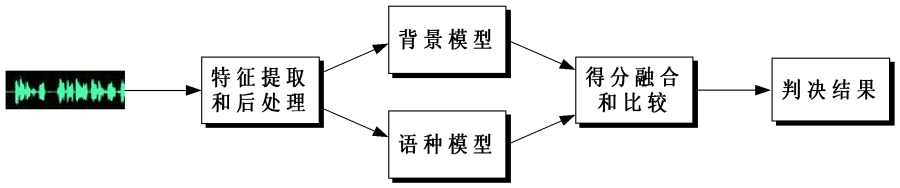
本研究利用语音声学信息和音位配列信息进行语种识别,首先通过建立高斯混合模型实现对语音声学特征的建模,然后结合语言模型,实现并行音子解码。
Two cues, i.e. acoustic information and phonotactic information, have been adopted in the language recognition system. The Gaussian Mixture Models (GMMs) was used to model the acoustic characteristics, and then followed by the parallel phone recognition with language models (PPRLM).

2006年参加了美国国家技术标准局举办的语种识别国际评测,并取得了较好成绩。
The group participated in the Language Recognition Evaluation held by the USA National Institute of Standard and Technology (NIST) in 2006, and got good grades.
|
汉语文语转换( Mandarin Text-to-Speech Conversion)
汉语文语转换的研究内容包括:字音转换、韵律参数预测和语音合成三个部分。
The research on mandarin text-to-speech is in three aspects: Text to PinYin conversion, prosodic parameter prediction, and speech synthesis.
| 字音标注主要解决多音字和多音词的注音问题。采取结合上下文信息及语法信息的多音字消歧技术,利用决策树和最大熵等模式识别方法,使注音正确率达到 99.82%。
How to deal with the polyphones is a challenge for the text to PinYin conversion. A context-dependent polyphone disambiguation technology was proposed, combined with the decision tree and maximum entropy methods, the accuracy can be improved to 99.82%.
|
| 韵律预测可准确估计合成语音的语调、节奏、重音的位置和时长信息等。本研究提出了将短语分析的结果用于韵律预测的方法,在韵律停顿预测中取得了较好的效果。
The prosody prediction is to estimate the intonation, rhythm, stress placement and timing. In the research the phrase analysis result is introduced in the prosody prediction. It can improve the performance of rhythm prediction.
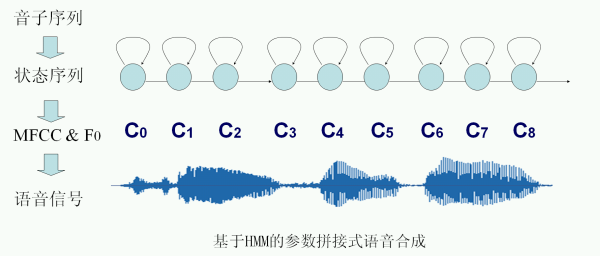
| 语音合成将字音标注和韵律预测的结果合成出语音信号。本研究重点探讨基于隐马尔可夫模型的语音合成方法,它所需存储空间小并具有较强的灵活性,合成效果较好。
Speech synthesis module generates speech signals based on the results of PinYin annotation and prosody prediction. The HMM-based parameter concatenation method has been investigated in order to satisfy the high performance.
| 
|
|
字幕检测、识别及检索技术(Caption Detection,Recognition and retrieval technology)
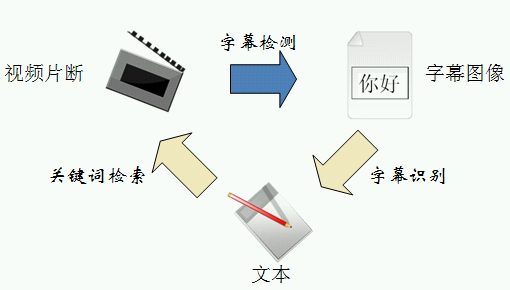
随着计算机技术、多媒体技术以及通讯技术的飞速发展 , 以图像、声音和视 频为主的多媒体信息迅速成为信息交流与服务的主流,于是基于内容的检索(Content Based Retrieval, CBR )技术也应运而生。而视频中的字幕信息(如新闻标题、节目内容等)包含了丰富的高层语义信息,这些文字的自动检测、分割、识别对于内容的理解检索有着重要的意义。
With the rapid development of computer, multimedia and communication technology, the multimedia information based on images, voice and video is rapidly becoming the main way of information exchange and service. Hence, Content Based Retrieval (CBR) technology has emerged. The captions in video (such as headlines, content, etc.) contain a wealth of high-level semantic information. Automatic detection, segmentation and identification of these words have very important significance for content understanding and retrieval.
基于视频的字幕检测和增强根据字幕的特殊性选择合理的特征,并利用视频中多帧间的冗余信息实现字幕的检测和增强。
Caption Detection and EnhancementChoosing reasonable features according to the particularity of caption, and combining the redundant information of multiple video frame to detect and enhance caption.
| 
系统框架(System Architecture)
基于统计机器学习的字幕识别提取小波变换的特征并使用隐马尔可夫模型和统计语言模型的识别技术相结合的机器学习方法,实现字幕文字的识别。
Caption RecognitionFeature extraction using wavelet transformation and the combination of statistical language model and Hidden Markov Model methods finally achieved the identification of caption.
|
实时人脸识别技术 (Real-time Face Recognition)
在针对视频字幕处理的同时,实验室同时开展了针对以人脸为目标的检测、定位及识别系统的研究。
We also do some researches on FACE such as detection, alignment and recognition.
实时人脸检测系统使用高效的AdaBoost区分性学习算法,并加以大量人脸及非人脸图片训练,使计算机能实时从视频中检测出不同视角的人脸区域以及非人脸区域。
Face DetectionBased on high effective and discriminative AdaBoost algorithm with lots of face and non-face images for training, the computer is able to detect multi-view face area from video stream.
实时人脸对齐系统采用经优化后的形变模型算法,使得计算机能在已知的人脸区域中实时定位人脸的五官,为之后的准确识别人脸提供先决条件。
Face AlignmentBy optimizing the deformable algorithm, the features of face are located real-time in the square of face.
| 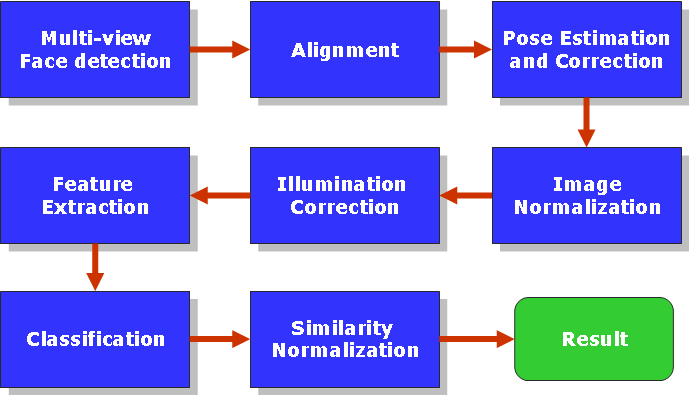
系统框架(System Architecture)
高鲁棒性的人脸识别系统采用基于Gabor小波变换的鲁棒特征提取,并结合AdaBoost学习算法,最终实现高效率、高准确度的实时人脸识别系统。
Face RecognitionFace recognition system, which combines the robust feature extraction and AdaBoost learning algorithm, realizes a highly effective and accurate real-time face recognition system eventually.
|
|


